AWS general datalake architecture
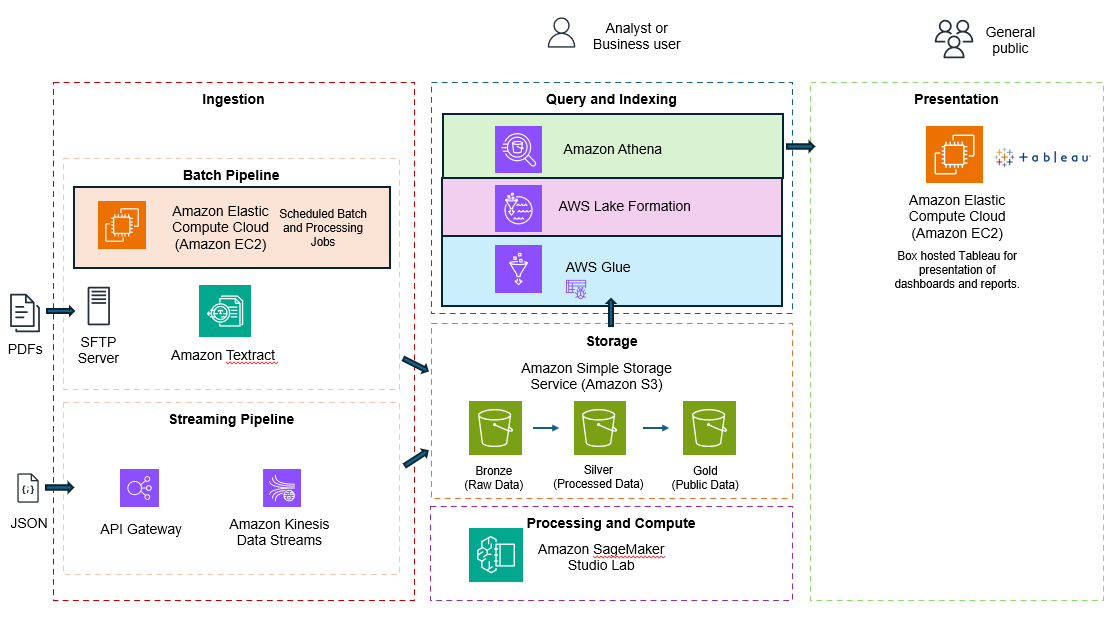
Batch Pipeline:
Designed to take incoming pdfs via sftp. A boto3 script would run hourly. This script would take pdfs from the sftp server, process them through amazon texttract (OCR the files). The results are then sent to the S3 bronze bucket.
Streaming Pipeline:
Designed to take streaming data. This is to take immunization data as json from the api gateway and push to a kinesis stream. The stream would be placed in the S3 bronze bucket. The file name would have a file format of YYYY/MM/DD/[time].json
Query and Indexing:
Starting from the bottom, the AWS glue service is a metadata store of the data in the Storage layer. A glue crawler would periodically scan and index the data in the buckets. The lake formation service would provide data governance. This would prevent PII or HIPPA data from being accessed by unauthorized users. Athena would take the sql query and query glue data catalog to data from s3.
Storage:
Data at rest would reside here. The data would first go the bronze bucket (raw data), next the data would move to Siver once processed and cleaned. Finally, data ready for the public was placed in the Gold bucket.
Processing and Compute:
Since it was a large amount of data we used sagemaker juyper notebooks with pyspark to process, clean. and transform the data.
Presentation:
Tableau was used to present dashboards. The dashboards would query Athena using a JDBC driver. The SQL query once processed returned a result set of the data residing the Gold bucket.